

















Veeva Data Cloud
构建 HCP 全景 “客观参考系”
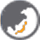
Veeva Data Cloud 整合了高质量主数据(OpenData)、多维度客户画像(Ultra HCP)与行业基准分析(HCP Access),构建起全方位的 HCP 的“客观参考系”。作为公有且可信的连通数据源,它不仅消除数据孤岛,更通过一套统一的参考坐标,校准企业内部视角的偏差,赋能端到端的 HCP 智能洞察,确保商业决策投入更准、响应更快。
为什么选择Veeva Data Cloud
-
全景数据坐标系
整合主数据、深度画像及行业基准,构建覆盖全面的动态全景地图,支持企业在全景视野中定位业务并发现资源配置盲点。
-
原生集成
与业务系统深度融合,消除数据清洗与传输损耗,确保洞察在工作流中即时转化为业务行动,显著加速决策响应。
-
结构化的数据底座
针对 AI 与高级分析设计的结构化模型,确立高质量数据资产,助力企业科学应对 AI 时代数据治理挑战。
-
 积累高质量数据资产,驱动 AI 规模化应用。
积累高质量数据资产,驱动 AI 规模化应用。建立结构化、可追溯的数据底座,解决数据碎片化难题,确保智能化决策具备确定的逻辑依据。
-
 穿透信息孤岛,实现全景化洞察。
穿透信息孤岛,实现全景化洞察。通过多维参考系识别关键 KOL 及高潜医生,补足未知领域的空白,校准资源投入。
-
 打破执行摩擦,驱动价值闭环。
打破执行摩擦,驱动价值闭环。通过原生集成将高质量洞察转化为业务流动作,推动策略敏捷落地,实现从战略预判到执行产出的高效增长。




常见问题 FAQ
Veeva Data Cloud 是专为医药行业商业化设计的中国数据云解决方案,也是企业数据资产底座的核心组成。它整合三大数据引擎:Veeva OpenData(主数据管理)、Ultra HCP(AI 驱动的动态多维画像)和 HCP Access(行业互动基准对照),三者通过统一的 Veeva ID(VID)关联,构建起覆盖全面的 HCP 客观参考系。
它解决的核心问题是:企业在制定商业策略时过度依赖内部历史数据和主观经验,缺乏客观的行业参照坐标,导致学术资源布局存在盲区。Veeva Data Cloud 通过一套统一的外部参考坐标,校准内部视角偏差,赋能以事实证据为基础的商业决策。
三者相互独立,可根据业务需求单独采购,也可组合使用:
Veeva OpenData:提供经过严格清洗与验证的 HCP/HCO 主数据,是最常见的入门产品,也是构建客观参考系的数据基础。
Veeva Ultra HCP:AI 驱动的多维学术画像与影响力评级,服务于战略客户分层(S&T)决策,可独立使用,也可结合 OpenData 提升数据关联深度。
Veeva HCP Access:基于全球 80% 生物制药企业真实学术互动数据生成的行业基准,帮助企业对照行业水平优化互动策略,可独立引入。
三者通过统一的 Veeva ID(VID)实现数据关联,组合使用可最大化数据价值,但每款产品均可独立交付业务价值。
AI 决策系统的输出质量直接取决于输入数据的准确性——”垃圾进,垃圾出”的问题在 AI 时代被显著放大。当企业使用 AI 工具进行学术互动建议、智能调度或 Agent 自动化决策时,错误或过期的 HCP 数据将直接导致错误的业务建议。
Veeva Data Cloud 采用 AI-Ready 架构,提供经过严格验证的结构化主数据底座,确保企业的 AI 应用建立在可信的事实基础之上。随着 2025 年《医药工业数智化转型实施方案(2025-2030 年)》的推进,高质量数据资产已成为医药商业化数智化转型的前提条件,而非可选项。

