Article
A Plan for Adopting the Commercial Content Kernel for Life Sciences
Commercial content managers have much to be excited about. The average days in review for content decreased by more than 25% to 16 days at U.S. biopharmas last year. EU companies held steady in the metric compared to the prior year. The number of review cycles was down across all markets globally.
Now, commercial teams seeking to sustain momentum as they produce more high-quality content faster can adopt a standard taxonomy called the Commercial Content Kernel for Life Sciences. The content kernel is a practical solution to simplify content management and create efficiencies for stakeholders, especially MLR teams. It’s also an important preparatory step for easier integrations, including adding AI applications.
Read on to learn how the kernel establishes a common ‘language’ for the industry to classify and categorize commercial documents and data — and why it’s the right time to standardize.
"Those who work in content understand that the ultimate goal for standardization is personalization, effectiveness, and the ability to measure — to give customers what they need when they need it."
The Commercial Content Kernel’s parent: Common Data Architecture
The Commercial Content Kernel — formerly the Commercial Content Taxonomy for Life Sciences — is part of the Common Data Architecture for Life Sciences (CDA). The CDA is a life-sciences-specific, open, and freely available standard for software applications, data products, and people. Its goal is to promote faster production and access to high-quality, relevant data and materials by enabling uniform data to flow cleanly between software systems and people.
For example, when all stakeholders share a standard data language, integration and analytics projects could become faster to build, easier to maintain, and more accurate. When amplified across life sciences, such standardization could expedite patient treatment and help improve outcomes.
CDA and the Commercial Content Kernel
CDA has multiple cascading data sets or ‘kernels’ designed to be small, easily understood, and easy to implement. Each data set, including the Commercial Content Kernel, consists of industry-standard definitions for a related group of entities, attributes, and drop-down lists. The content kernel’s document types include articles, brochures, emails, presentations, press releases, videos, and more.
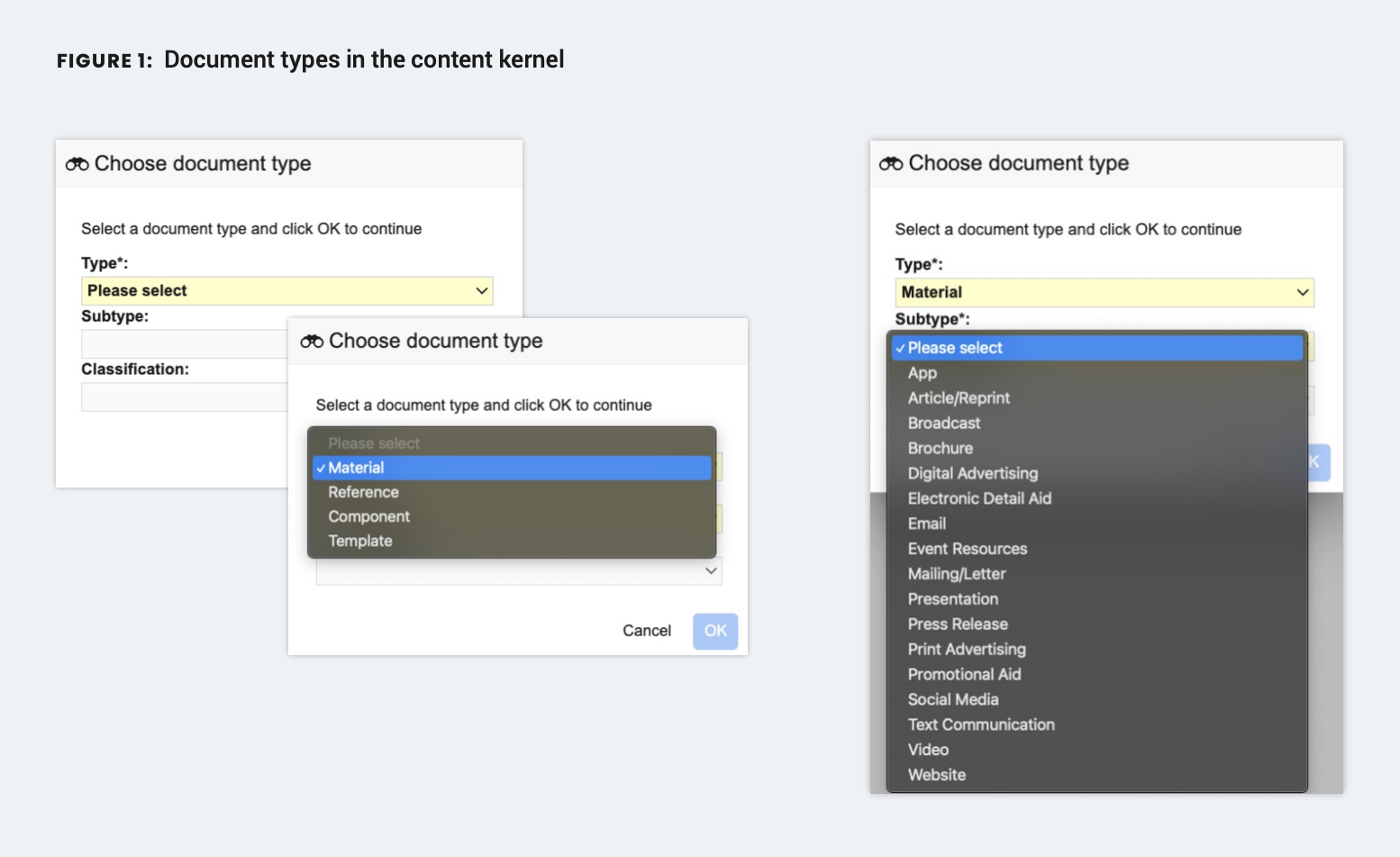
The acute need for an industry-standard taxonomy
Efforts to standardize taxonomies in life sciences have stagnated in recent years, leading to increased complexity in companies and at the industry level. Biopharmas label millions of documents in all-encompassing categories such as “promotional piece,” “MLR,” or “other.” Highly granular taxonomy models, on the other hand, result in 7,000 unused labels industry-wide. It’s easy to find examples of unnecessarily complex classification. For instance, biopharmas use 68 ways to describe an “electronic detail aid.”
Regulatory bodies also follow different approaches to document classification, and some authorities don’t require a defined content type at all, leading to more inconsistencies. Absent a common global language to classify content, it will be increasingly difficult for companies to provide the content healthcare professionals (HCPs) need on behalf of patients. In addition, efforts to measure and improve content could suffer from inconsistent taxonomy.
The roadblocks to standardization are unique to each biopharma, yet often include siloed departmental structures, resistance to change, and the challenges of developing a comprehensive taxonomy that addresses commercial content’s diverse and changing nature. Until now, biopharmas had no option but to build their unique taxonomy.
The document hierarchy in the Commercial Content Kernel is already defined, so teams get a head start. They access it within their typical workflows in Veeva PromoMats, facilitating fast decisions about how to label documents and data. MLR teams are clear on what asset types they’re reviewing, which makes it easier to get the correct information to HCPs and patients faster. MLR teams that enjoy better review and approval processes will expedite compliant content to market.
Veeva created the open-source, industry-standard content kernel and supports it with videos, white papers, and other educational materials to help rein in:
- Content types numbering nearly 300,000, creating duplication, inconsistency, and confusion industry-wide
- Content subtypes established before content tagging strategies and technologies became available
- Different categories, tags, and metadata making it challenging to organize content into associations logical to customers, the business, and the industry
The new system’s advantage is its two-level hierarchy: content type and subtype (Figure 1), with accompanying descriptions and a field to capture the intended use and audience. The taxonomy accommodates whole documents/materials and their building blocks — for example, references to support claims, digital asset management components, and templates.
Determining when to adopt the content kernel
Preparing to standardize your taxonomy starts by assessing your challenges and goals. Use the following Q&A framework as the foundation for your change management strategy and readiness assessment.
First: Identify your biggest challenges
Identify your organization’s most significant challenges and inefficiencies when it comes to content; for example:
- Data quality issues: Does your taxonomy lead to inconsistent, inaccurate, or redundant data?
- Inefficient content management: Does your taxonomy slow content creation, retrieval, or distribution?
- Lack of MLR efficiency and speed: Can reviewers quickly understand the content type they are reviewing to ensure regulatory compliance?
Next: Clarify your strategic content goals
Pinpoint your organization’s strategic goals for content and validate them with key stakeholders; for example:
- Enhanced data insights: Deeper insights into content performance through improved analyses and reporting
- Improved content efficiency: Streamlined content creation, MLR reviews, and high-quality targeted content
- Empowered teams: The ability to quickly and easily onboard new users, agencies, and partners to equip teams for success
- A more connected IT infrastructure: Integrations that enable systems to speak the same language and share data, paving the way for scalable AI-influenced content
Steps to standardize your content kernel
Veeva’s taxonomy adoption program is focused on existing Veeva PromoMats customers. Organizations new to Veeva PromoMats — those implemented with the second release of 2024 — start with the content kernel document drop-down list (Figure 1) set to “Active” by default. Current customers ready to migrate will access the standardized document list directly within Veeva PromoMats but must activate the drop-down when ready.
Veeva’s Professional Services and Business Consulting teams developed a comprehensive methodology and an adoption program (Figure 2) to ensure a smooth transition.
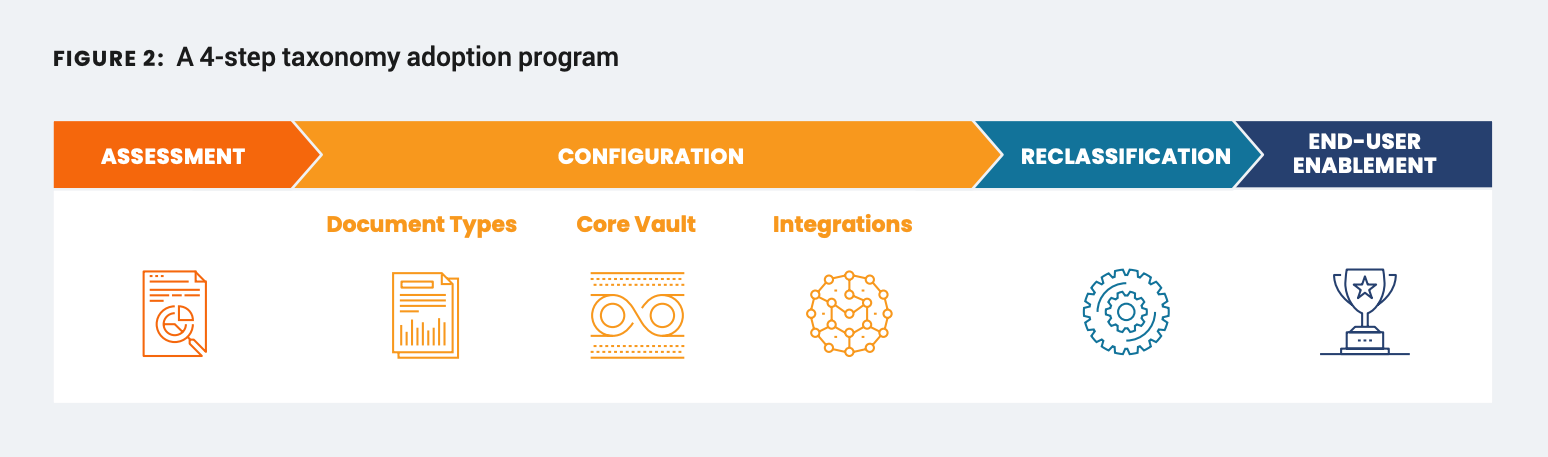
Assessment
Veeva experts will thoroughly analyze your existing configuration and business processes, map your current taxonomy to the new industry standard, and assess any potential impacts. In looking at your end-to-end business process (including the integrations), your Veeva partners will identify the types of content you handle via different processing or distribution in and outside of Vault.
This step also marks the start of conversations about the reclassification approach to help you determine what to do with your existing documents.
Configuration
Based on the insights from the assessment phase, the Veeva team will configure the new document types, optimize and reconfigure the core Vault elements connected to them, and reconfigure any affected integrations.
Reclassification
In this step, Veeva will reclassify your existing content to the new taxonomy structure, ensuring data integrity and accuracy. Notably, this will entail deciding whether you’ll reclassify all your content or only currently approved non-expired content — or whether to adopt the new taxonomy for only new content going forward.
End-user enablement
Veeva helps update your training materials, documentation, or standard operating procedures and comprehensively trains users in Vault to use the content kernel. Importantly, the Veeva teams help socialize the ‘why’ behind the change.
A change management strategy
To speed the adoption process and minimize implementation resources, start on a tactical level by bringing stakeholders into the fold with education and training. Veeva provides standard definitions of each document type in the content kernel. You can use this ‘key’ as the basis for change and training materials, so all participants speak the same language and there is clarity about what they mean.
You can begin by sharing compelling reasons (Figure 3) for adoption that align with users’ incentives and demonstrating how the new taxonomy fits into their existing workflows. Then, you can help stakeholders become your advocates by discussing the ease of use and access to the open-source, agnostic taxonomy structure within PromoMats.

Taking control of your content
As content volume continues to climb, adopting the Commercial Content Kernel for Life Sciences is a strategic investment in better managing and streamlining your content supply chain. By following these steps, you can successfully implement the new taxonomy in your organization and reap the benefits of improved document and data quality, consistency, and accessibility.
Ready to adopt the Commercial Content Kernel for Life Sciences? Visit our resource center to get started.