Nitro Blog #1-1: 散在する、未統合のデータ
データ活用における困難さ
ライフサイエンス業界は現在、国内外を問わず規制やガイドラインの厳格化といった様々な構造変化の渦中にあります。一方、ソーシャルメディア、IoTなどの技術革新を背景に利用可能なデータ、情報は加速度的に増加しています。こうした理由からもライフサイエンス企業は、収集可能なデータを活用して、これまで以上に効率的な経営が求められています。
これらの状況を受けて、ライフサイエンス企業各社はデータ活用の重要性をすでに認識している一方、なかなかスムースでスピーディな活用には至っていないのが現状です。そこには、以下のような障壁が存在しています。
散在する、未統合のデータ
分析に使用するデータが一箇所に集約管理されておらず、様々なシステムで独自に運用されているという状態になっていないでしょうか? データが格納されているシステムがバラバラであれば、顧客や製品を表すコードも別の体系になりがちであり、その統合は一筋縄ではいきません。
また「うちは集約管理できている」という企業様にも詳しくお話をお伺いしてみると、複数のデータソースシステムから直接BIツールにデータ連携を行い、BIツール上でデータを集約している、というケースもあります。このようなシステム構成を選択しているケースで「新たに統計解析ツールを使用したい」、「AIを活用したい」となった場合、どのような事が起こるでしょうか? BIツールでデータを集約しているので、一見単純に行えそうにも思えますが、実はそうではありません。新しいツールを使用開始するたびに、データソースの数だけ新しいデータ連携の構築が必要になります。理論上、アプリケーション数が n 個ある場合、 n 個をそれぞれ連携させるためのデータ連携本数 l(n) は n(n-1)/2 本になります。l(2) = 1, l(3) = 3, l(4) = 6 と少ないアプリケーション数では穏やかな増加ですが、 少しアプリケーション数が多くなるだけで、 l(10) = 45, l(11) = 55、すなわち1つのアプリケーションを追加するだけで構築必要な連携数は10本に激増します。いわゆる「組み合わせ爆発」の問題です。
図1: BIツールでのデータ集約
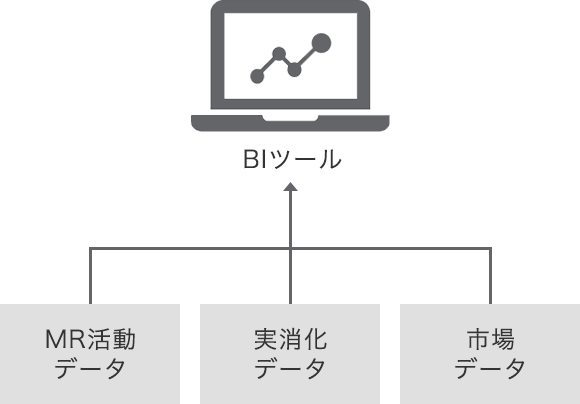
図2: データ連携本数は指数関数的に増加
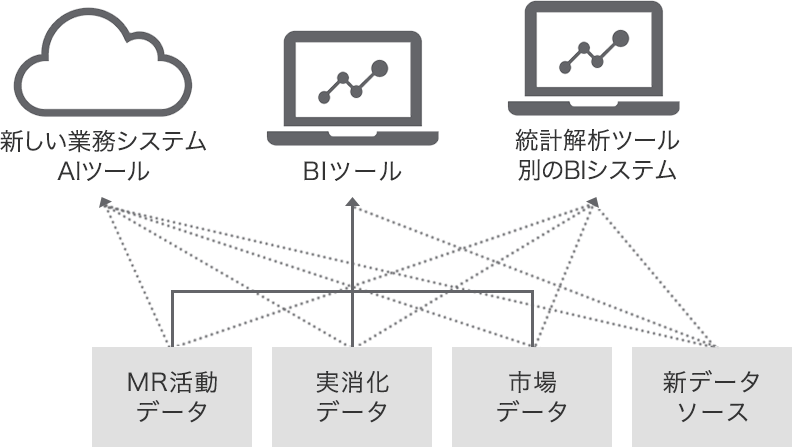
技術革新によってデータ活用のバラエティは今後ますます増大し、そのインターバルは短期化していくでしょう。このスピードに追随し、技術革新のメリットを享受するためには、システムアーキテクチャ(アプリケーションの構成)を短期間・低コストで変化させることを可能にする仕組みが必要不可欠になると考えられます。そのためにはデータソースからデータを集約し、データ活用ツールへの配信を一手に担う「データハブ」を構築するというアイディアがあります。すべてのデータを一箇所に集約していれば、既存のシステム構成に関わらず追加する必要のあるデータ連携本数は常に1本になります。
ではこのようなデータハブはどのように構築するべきでしょうか。技術的解決方法は単純であり簡単で、各社でただ一つのデータ保管場所=「データウェアハウス(DWH)」を用意し、そこにデータを集約すれば良いのです。しかしこれを阻むのは技術的な制約ではありません。企業内の各部署で利用したいデータやその形態が異なるため、各部署から異なる、相矛盾する要望が偶発的に出現し続けます。それに都度適切な(と思われる)対処をしていくと、全体としてデータの散在、未統合を引き起こしてしまいます。これを実直に解決するためには、データ管理についての強力な統制(ガバナンス)と、非常に多くの部署間調整コストが必要になってしまいます。
図3: データハブとしてのデータウェアハウスでデータ連携を簡素化
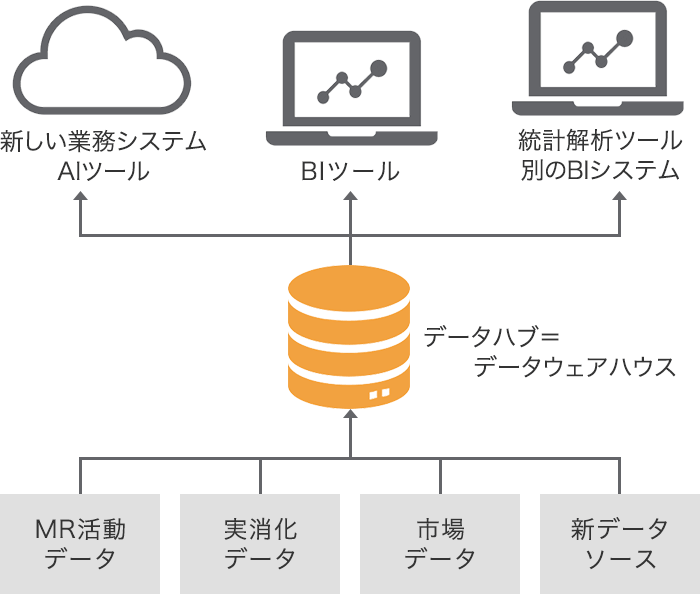
こうした課題に対して、Veevaは異なるアプローチをご提案しています。実消化データ、市場シェアデータ、MR活動データなど、ライフサイエンス企業が使用するデータ群を予め標準化し、1つのDWHの中にデータモデルまで事前定義したものを使っていただくというやり方です。このDWHを採用すると決定しさえすれば、必然的にこれらのデータを一箇所に集約することができるようになっております。
次回は、引き続きデータ活用における難しさとしてあげられる、システムの硬直性について考えていきます。
Nitro Blog #1-2 を読む