Optimizing the Sponsor-CRO Data Flow with a Centralized Clinical Data Workbench
3,600
manual queries eliminated
300
hours saved automating queries
90%
of SAS listings eliminated
As the volume and variety of data collected in clinical trials increases significantly, the legacy systems and processes used to manage clinical data have become a bottleneck that slows trial progress. This is why streamlining data ingestion, cleaning, and review is a critical focus for sponsors looking to accelerate the development of their therapeutic products. A late-stage clinical biopharma company specializing in immunological therapies, partnered with Atorus, which is providing clinical analytics and technology in addition to traditional CRO services.
Atorus and the late-stage biopharma use Veeva CDB to centralize data review, automate workflows, and have easier access to complete and concurrent data.
We have a really great partnership,” says the biopharma’s head of eClinical programming. “We have worked together to build Veeva CDB into what we need.”
“We don’t consider ourselves as just sponsor and CRO. We’re partners. We’re able to be very transparent and give each other feedback,” adds Meg Richie, vice president of global clinical data management at Atorus.
Barriers to smooth data flow
In a poll of clinical data management experts at the Veeva R&D Summit session in Boston, the majority (41%) reported using nine or more data providers in their clinical trials, with only 4% using one to two providers. In addition to managing many third-party providers, data managers must centralize all data across electronic data capture (EDC), connected devices, and eCOA apps. This data needs to be collected, combined, and harmonized so it can be reviewed in aggregate. In most cases, this process is inefficient, involving multiple handoffs between clinical data and operations – something that many sponsors and CROs are invested in reducing. Data managers put in significant manual effort to merge, map, and transform data for downstream purposes, in order to gain any operational insights.
Once data has been aggregated, data review often takes place in silos. Reviewing ‘offline’ listings from SAS or similar programs takes a lot of manual effort and can result in inconsistencies. The biopharma’s head of eClinical programming describes the challenge when errors occur: “Having to get our programmers to rerun their programs for SAS listings…you don’t want to waste their time on that. We can much better utilize their time.”
Veeva CDB is a clinical database that is designed to address these challenges, by automating data aggregation, harmonization, and cleaning.
Enablement and process optimization
The late-stage biopharma started using Veeva CDB in 2023, and at the time were fully outsourced with a CRO. The company moved to a more hybrid model following implementation, working with Atorus as a functional service provider (FSP). After consultation with Veeva, the biopharma decided to take an iterative approach to implementing Veeva CDB, with two studies currently rolled out and a third underway, with several listings and auto checks in production. “It’s nice we can use an iterative approach — you can prioritize the data you most want to take advantage of Veeva CDB for, and get the experience of getting things into production while you expand,” explains the head of eClinical programming.
This form of enablement allows the programming teams at the biopharma to learn the system and optimize processes for the next batch. The Atorus team is embedded within this model: “Our staff feel like they are part of the team,” says Richie. “They are part of the enablement and learning more about Veeva CDB. Our programmers and data managers are learning directly from the biopharma team .” When introducing a new system, managing the required changes to internal processes can be daunting. To facilitate this, Veeva provides guidance on the required updates to existing standard operating procedures (SOPs). As part of enablement, the biopharma has used Veeva’s templates and documentation to update its processes. The biopharma’s head of eClinical programming explains: “Thus far, we’ve worked through Veeva’s process, which has been great. Now we’re going to use that to help us update our processes internally and decide how we want to document things and move forward.”
As the late-stage biopharma launches new studies using the clinical data workbench, they plan to onboard data providers in Veeva CDB to remove the need for offline tracking of data issues. Their head of eClinical programming notes how the change in process so far has been minimal for data providers: “It has been great having them be able to provide that data directly, and it’s as simple as how they were providing it previously.”
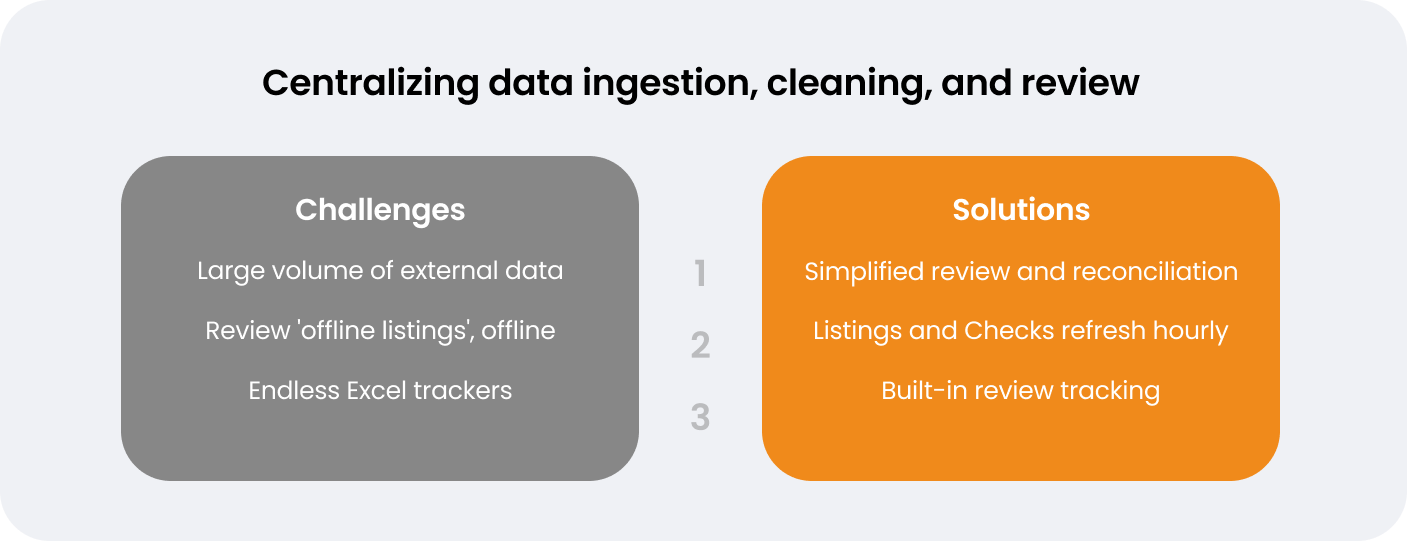
Minimizing manual tasks with automation
The first challenge the biopharma wanted to address was aggregating their large volume of trial data. “This is a really good use case for Veeva CDB,” notes their head of eClinical programming. “Having that data in Veeva CDB aggregated with our EDC data makes the review much simpler and faster. That’s been really helpful for us,” they comments.
“Having that data in Veeva CDB aggregated with our EDC data makes the review much simpler and faster. That’s been really helpful for us.” – Head of eClinical programming and solutions, late-stage biopharma
Having a centralized clinical workbench means the biopharma’s team can reconcile and review data from all sources in one location. Veeva CDB’s change detection feature automatically identifies data that is new or changed, allowing teams to avoid spending time on data that has already been reviewed: “In Veeva CDB you can see exactly what’s changed, and that really helps,” says the head of eClinical programming.
The team also uses Veeva CDB’s auto checks feature to automatically identify errors and create and close queries. The head of eClinical programming outlines the impact this has had: “We have eliminated about 3600 manual queries that we were previously carrying out, which has saved us around 300 hours of manual effort.” Listings and auto checks refresh hourly, meaning the Atorus team can access clean aggregated data with fewer transformations and less data lag. “Our SAS programmers really find value,” notes Richie. “By using Veeva CDB, they have cut 90% of the need for SAS listings.”
“We have eliminated about 3600 manual queries that we were previously carrying out, which has saved us around 300 hours of manual effort. Batch querying is one of our data manager’s favorite features of Veeva CDB.” – Head of eClinical programming and solutions, late-stage biopharma
The ability to open and close queries in batches has also saved teams a lot of time: “Batch querying is one of our data manager’s favorite features of Veeva CDB,” notes the head of eClinical programming.
“By using Veeva CDB, SAS programmers have cut 90% of the need for SAS listings.” – Head of eClinical programming and solutions, late-stage biopharama
Improving access to complete and current data
For Richie’s team at Atorus, working with ‘offline’ data produced a lot of challenges. Data managers would need to wait for programmers to re-run listings, whose time could be more optimally spent on other activities. Listings refresh automatically on the latest data when they are opened in Veeva CDB or exported downstream, saving programming resources and giving data managers better visibility of available data.
Richie outlines the advantages of this: “Veeva CDB allows us to do more real-time data cleaning and move checks upstream. Having the case report form (CRF) and external data in one place adds visibility and provides that holistic picture. That has definitely given some time savings, and has been a great tool for data managers.” The filtering and sorting capabilities in Veeva CDB also give data managers the same options to manipulate data in the ways they would have done previously in Excel spreadsheets.
Having a unified set of complete and concurrent data that can be easily accessed opens the door for partners to create custom views that are tailored for downstream audiences. Leveraging Shiny, Richie aims to use data from Veeva CDB to create targeted visualizations for downstream audiences. This will allow analytics and engineering teams to deliver the right reports to stakeholders based on what they need to see for their individual deliverables and objectives, using data that has already been aggregated and cleaned in Veeva CDB.
Discovering untapped potential
The biopharma and Atorus are already thinking of ways to expand their use of Veeva CDB’s capabilities to unlock further efficiency.
The biopharma sees additional opportunities for automation. They currently use Veeva CDB’s ability to pull coded information from the medical dictionary to create auto checks for prohibited medications (something that would not be possible using medication verbatim names entered by sites into EDC). Today, this check generates a query when a prohibited medication is identified. But the biopharma’s head of eClinical programming sees potential to extend the use case to automate identification of protocol deviations in the future. “That’s a great place where we can expand our usage,” they comment.
“We’re able to do a lot of complex things, and I’m sure there’s even more,” the head of eClinical programming notes. “That’s one of the great things about Veeva CDB – we’ve done a lot, but there’s so much more that we can do. We’re definitely looking forward to expanding that,” they concluded.
Learn more about how Veeva CDB accelerates and streamlines data aggregation and cleaning.