Blog
Solving Clinical Data’s Volume and Variety Challenge by Easing Collaboration with Data Providers
Jul 07, 2023 | Jason Driesbaugh and Edward Jones
Jul 07, 2023 | Jason Driesbaugh and Edward Jones
Part I of the series: “Taking a Modern Approach to Aggregate, Clean, and Transform Clinical Data”
Over the past few years, both the volume and the variety of clinical trial data have been increasing rapidly. Currently, 50-70% of this data comes from third-party sources outside of EDC.1 Data managers have had to rely on manual approaches, and multiple spreadsheet trackers, just to keep track of multiple data sources and datasets. Ensuring that all the data is valid and accounted for has become a major headache for data managers and their teams.
But one of their greatest challenges is aligning data from different sources and different data models into one cohesive structure. Existing industry standards and data models require considerable transformation to align the source data with the model, so fitting raw data to these models is time-consuming.
Until recently, no options were available to help data managers address this challenge, especially in light of the increase in both the volume and variety of clinical trial data. Data teams often used statistical computing environments to aggregate and reconcile data, but these environments relied on bespoke code developed independently at each sponsor or CRO. In addition, they did not allow data to be cleaned from within the system, and the data connectors they required were often fragile.
Simple ingestion, ensuring complete and concurrent data
To solve this challenge, Veeva’s DQS clinical data workbench uses a simple data model that brings all study data, whatever its source, into a consolidated data structure that serves as the backbone for each trial. With this structure at its core, Veeva DQS ensures that data from various sources is aligned consistently, while still accounting for the uniqueness of each study and vendor data source.
The next goal was to find the best way to bring complete and concurrent clinical data into the system. Having all the study data and ensuring that it was up-to-date would provide data management teams with easy, quick access to all of the study data in one place, eliminating the need for them to try to piece together an overview of all study data. It would also remove the limitations of stale data seen in traditional approaches to ingestion.
However, the ingestion process needed to be as simple as possible, to allow third-party providers to get data into the system quickly, without additional programming or major transformations.
Focusing on consistency and simplicity, Veeva took a commonly-used best practice for manifest-based data definitions and applied it to data transfer and ingestion, an approach that had never been tried with clinical data before. The manifest file aligns incoming data to the study backbone, making it easier for data providers to modify the source data definition as protocol updates are made. Veeva also created a manifest builder to make it even easier for data providers to generate a manifest file without needing to know how to manually create their own.
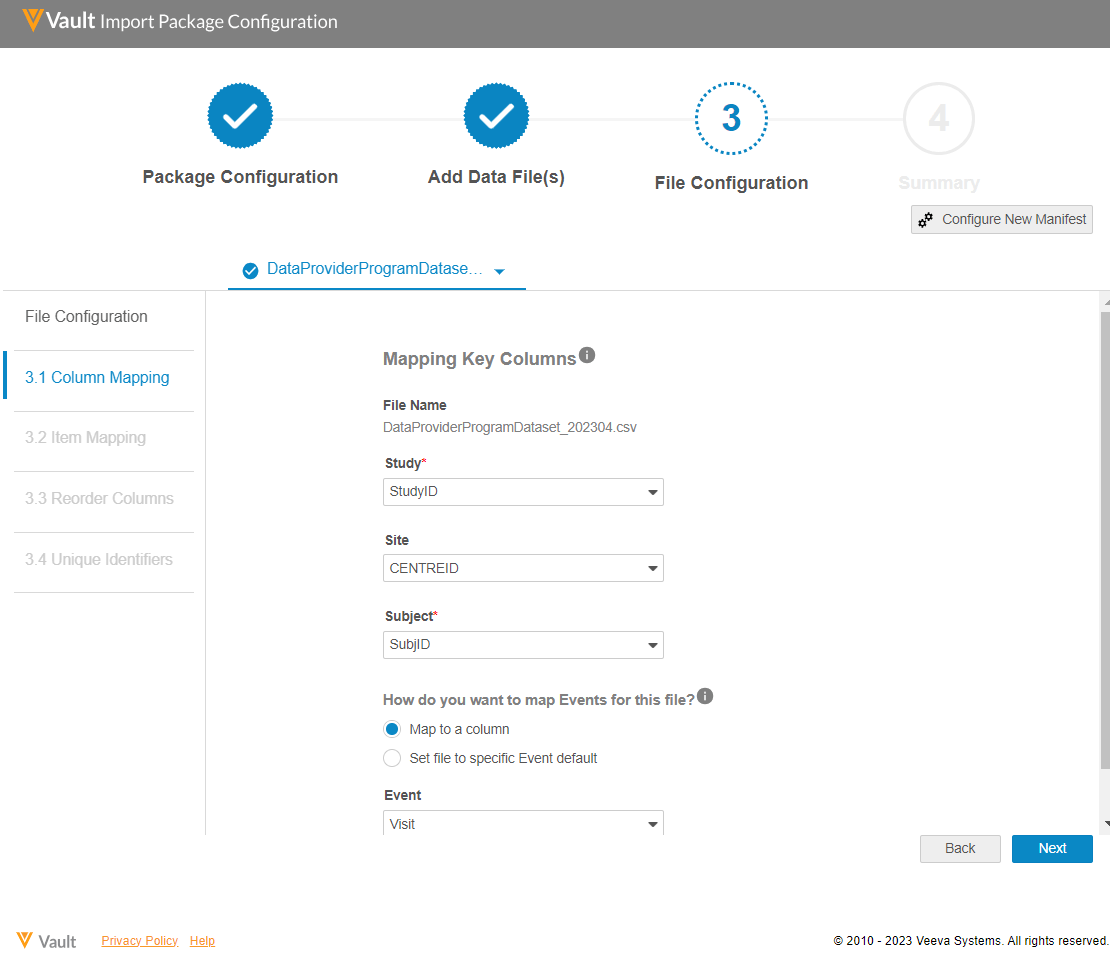
Data providers indicate which columns in their CSV data import files map to key fields in the Veeva DQS study backbone.
Once key columns and data items have been mapped, the resulting manifest file is stored and reused every time the data provider sends an updated data file. Upon ingestion, the data is then instantly aligned to the study backbone. Any row of bad or duplicated data is automatically rejected and recorded in an error file for the data provider to review and fix, eliminating the need for any additional oversight or effort from the study data manager. Applying the manifest and study backbone achieves the following:
- Allows data providers to use their preferred structure for incoming CSV files, and to update it if/when changes occur.
- Eliminates the need for study teams to build or maintain custom connectors to data providers, or to track data imports in separate spreadsheet trackers since notifications are sent each time data is delivered.
- Offers data managers the assurance that their trial data is complete and accessible in one place.
- Guarantees that data teams receive the most up-to-date, concurrent view of data across every data source, without any delays in access.
Partnering for success
While the manifest builder is designed to be as intuitive as possible for data providers, it also offers data managers the assurance that their external data providers are well-equipped to assume the responsibility for getting their data into Veeva DQS.
Companies that join the Veeva DQS Data Provider Program receive the training and support they need in order to use the manifest builder and other key functionality effectively, ensuring smooth data delivery and management within Veeva DQS and maximizing customer success. Sponsors and CROs who receive data from participating data providers can be confident that it will be delivered seamlessly, with minimal need for intervention.
Leaders within the program, meanwhile, gain a unique opportunity to advise and shape industry processes, systems, and data delivery. Close collaboration involving sponsors, CROs, and data providers will be essential if the industry is to continue to innovate and improve the way it aggregates, cleans, and transforms clinical trial data.
Click here to learn more about Veeva DQS or the Veeva DQS Data Partner Program.
Read Part II of the series, “Simplifying the Complex: Optimizing the Data Model for Clinical Data Cleaning.”
1 The Evolution of Clinical Data Management to Clinical Data Science. SCDM paper, 2019.